
Huh, your comment made look if there were personalized recommendation algorithms running on lemmy. From what I found, it appears that Lemmy does not use personalized recommendation algorithms : https://join-lemmy.org/docs/contributors/07-ranking-algo.html
The specific function used for ranking is here : https://github.com/LemmyNet/lemmy/blob/4ba6221e04ab3e186669aeaa890d23b1e3f3d1a9/crates/db_schema/replaceable_schema/utils.sql#L18
I’m wondering how hard it would be to adapt the code to customize the score for every user, instead of it being global.
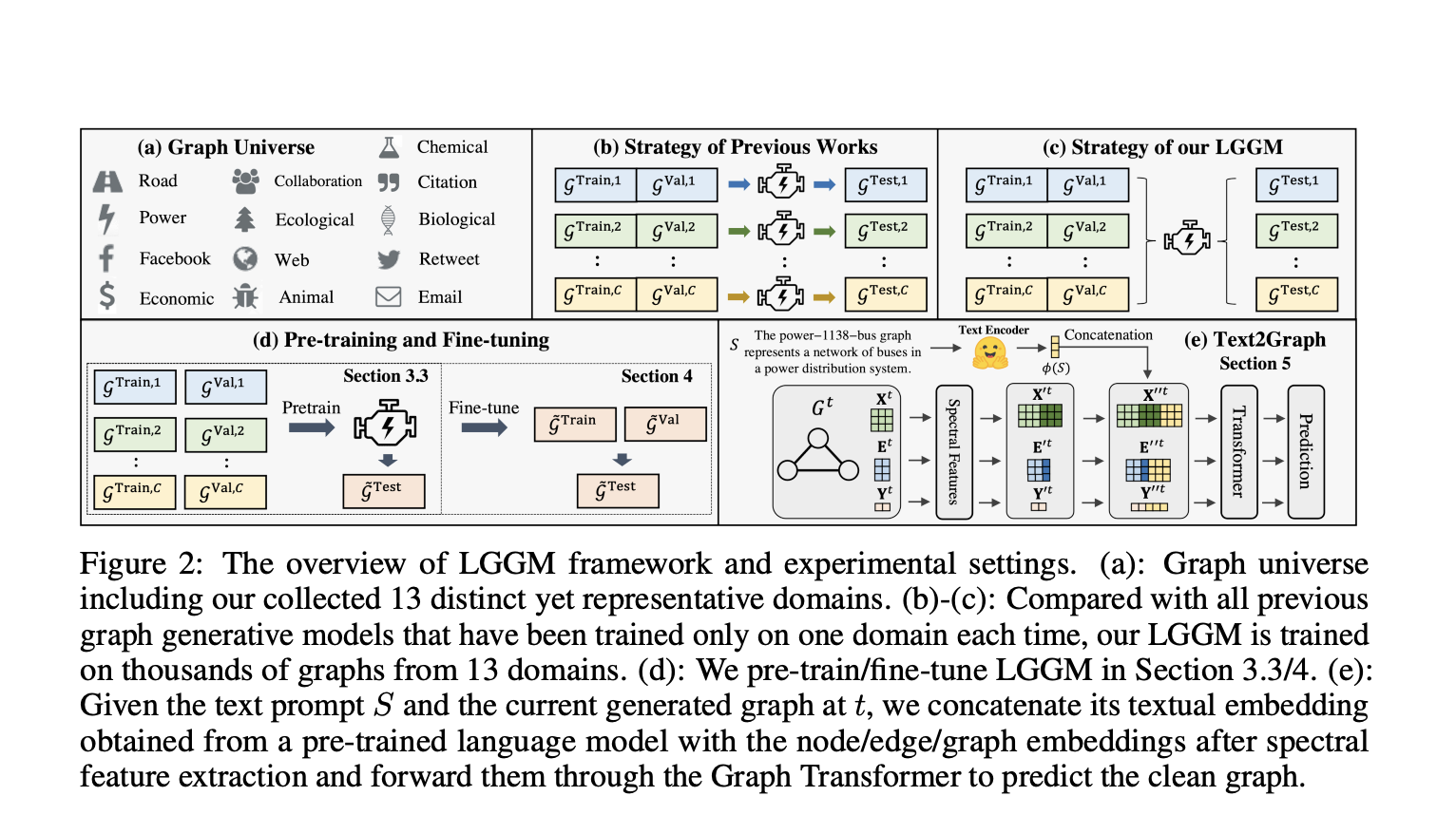
I makes it look like the advancement here is finding methods to efficiently use sets of graphs which are an order of magnitude larger than prior methods could use for training? They also seem to have used more sets of graphs than prior models across a wider set of domains. Am I reading this correctly?
I find it challenging to gauge the paper’s impact fully, as this isn’t my area of expertise. However, the ability to use diverse graphs in a single model surprised me and seemed worth sharing.














{kind=link}
They’ve got thunderbird which is as far as I know the only serious alternative to outlook.